

Your AI SDR/Sales Agent Looks Efficient, But It Might Be Shrinking Your Total Addressable Market
AI Sales Development Representatives (SDRs) have rapidly entered the B2B mainstream, promised as a silver bullet for scaling account coverage, personalizing outreach, and maintaining CRM hygiene without a linear increase in headcount. The value proposition is backed by sobering data: The 7th edition of Salesforce’s State of Sales Report notes that reps spend roughly 60% of their time on non-selling activities like manual research and data entry. AI agents are deployed precisely to reclaim this lost capacity.
However, these automated agents are typically evaluated on surface-level execution metrics: bounce rates, deliverability, and initial reply rates. On paper, AI SDRs routinely outperform humans on these dimensions. However, this efficiency is often a manufactured illusion.
To protect deliverability, an AI prospecting agent assigns confidence scores to contacts, quietly filtering out records that appear incomplete, risky, or difficult to verify. But because these AI agents lack continuous CRM data enrichment and nuance-based judgment required to patch missing fields or verify stale titles in real time, they default to risk aversion. While this sanitizes the outreach pool and inflates success percentages, it frequently cannibalizes commercial opportunity. By algorithmically narrowing the prospect list, the system silently contracts the company’s total addressable market (TAM).
The consequences of this invisible filtering rarely appear overnight; instead, they manifest one or two quarters later as an unexplained, systemic pipeline gap.
Why the AI Sales Agent’s Performance Metrics Improve when the Prospect List Shrinks
An AI SDR excludes the records that fall below its threshold confidence score. Common exclusions include:
- Weak or unverifiable email addresses
- Ambiguous or outdated job titles
- Thin or missing firmographic data
- Not reachable LinkedIn profile
- Low ICP (Ideal Customer Profile) fit or weak intent signals
Bounce rate, deliverability, and reply rate are ratio-based metrics. If the system removes risky contacts from the denominator, each ratio can improve even when the messaging and targeting remain unchanged.
There are multiple valid operational reasons for this behavior. For instance, mailbox providers now penalize poor mail sending practices more aggressively. Google’s sender guidelines require spam complaint rates to remain below 0.3%, and repeat violations can damage a sender’s reputation. Validity’s 2025 Email Deliverability Benchmark Report found average global inbox placement near 84%, meaning roughly one in six legitimate emails may not reach the inbox.
Excluding risky records undeniably protects the sender’s domain. The strategic friction arises when this exclusion principle is applied blindly by an algorithm. Rather than triggering an automated workflow for CRM data enrichment to repair and rescue these flawed records, the system simply deletes them from the sequence.
That reduces market coverage, and most dashboards do not show what was skipped. Most confidence thresholds are configured during onboarding, often using a vendor default. Once live, they are rarely reviewed. So, if that threshold does not account for an AI sales agent’s blindside, your TAM and revenue suffers.
Why Hard-to-Verify Prospects Can be Critical to a Sales Team
A low-confidence record is not necessarily a low-value prospect. High-value targets are often the most insulated, resulting in data footprints that require manual investigation to validate.
B2B contact data (technographics, demographics) decays quickly. Linear automation tools struggle to account for this decay. For example, when a key stakeholder gets promoted from “Manager” to “VP” or when an officer switches departments, their email address may be unverified, and their title may remain ambiguous in public registries. To protect deliverability metrics, the AI would filter this contact out.
At the same time, B2B purchases are rarely solo decisions. Most deals involve a buying committee across finance, operations, procurement, IT, legal, and leadership teams. If an AI outreach agent excludes a contact because the record is incomplete, it may remove someone who influences budget, approval, or technical sign-off.
The problem is especially visible in the mid-market. Large enterprises usually have stronger public footprints and richer third-party data. Mid-market companies often have thinner public profiles even when their budgets and buying intent are strong. This makes automating prospect verification harder because when automated systems optimize strictly for data hygiene, they inadvertently strip away the nuance required to navigate complex B2B hierarchies. A stronger prospect list building and verification process combines validation with continuous CRM data enrichment, so high-friction, hard-to-verify records are reviewed before they are removed from the outreach pool.
The Cost of Trusting AI SDRs Blindly Appears Later in the Pipeline
IBM noted in early 2026 that poor data quality often manifests downstream as lost revenue, missed opportunities, and operational inefficiencies. Automated outbound follows the same pattern.
Prospect filtering happens at the top of the funnel. The revenue impact appears much later. By the time the sales team sees a weaker mid-market pipeline, fewer qualified meetings, or lower opportunity creation, the original cause may be buried inside a confidence threshold set months earlier. A skipped record does not fail inside the sales process because it never enters one. It disappears before outreach, before response tracking, and before pipeline attribution. That makes the loss difficult to measure.
This is why the original filtering decision should not be treated only as a deliverability safeguard. It also functions as a market-access decision. If that decision is not reviewed, the system may continue protecting campaign metrics while silently limiting future pipeline.
How to Audit what the AI SDR Attempted and Skipped
The first step is to make the skipped volume visible. Compare the list provided to the AI prospecting agent with the contacts the agent actually attempted to reach. The difference shows how much of the market was excluded before outreach began.
The key metric is skip-rate (skip-rate = contacts skipped ÷ contacts eligible).
Track skip-rate alongside bounce rate, deliverability, reply rate, meeting rate, and pipeline contribution.
This audit should answer four questions:
- How many contacts were eligible before filtering?
- How many contacts were attempted?
- Which contacts were skipped? (Sorted by segment and seniority.)
- Why were they skipped? (Each skipped record should include a reason for its skip.)
What a High Skip-Rate Indicates about Your Prospect Data Quality
A high skip-rate should be read as a diagnostic signal. It shows that a large portion of the prospect database lacks sufficient reliable information for AI-driven prospecting to act on it with confidence. In most cases, the issue is not the AI SDR itself, but the quality, completeness, and freshness of the data it has been given.
For instance, a single-digit skip-rate may reflect routine data gaps. A double-digit skip rate concentrated in a single segment signals a coverage problem. For example, if the overall skip rate is 7% but the skip rate for mid-market operations leaders is 28%, the virtual SDR may be excluding a commercially important buyer group.
The causes are usually easy to identify once skipped records are reviewed. Job titles may be outdated, seniority fields may be missing, email validation may be weak, or contacts may not be linked to the right accounts. In other cases, firmographic data is incomplete, duplicate records create conflicting signals, or static data providers have not captured recent changes at the company.
These Issues Point to Systemic Database Decay
AI systems depend on the quality of their inputs. Gartner reported in 2025 that 63% of organizations either lack or are unsure they have the data-management practices needed for AI. Gartner also projected that 60% of AI projects unsupported by AI-ready data will be abandoned through 2026. IBM also reported that 43% of operations leaders now rank data quality as their top data priority and noted that AI systems inherit and amplify weaknesses in the underlying data.
The same principle applies to AI sales outreach automation. When the contact database is incomplete or outdated, the confidence model filters out records it cannot trust. Without review, those exclusions become part of the operating model.
Improving CRM data quality via frequent, in-depth B2B data enrichment changes that outcome. As more records become sufficiently complete for verification, more relevant contacts become available for outreach, and the digital sales rep can operate on a broader, more accurate set of prospects.
But resolving this requires shifting from passive data collection to an active CRM data enrichment model. The goal is not just to add more fields, but to make each record more useful for segmentation, prioritization, and outreach decisions. A structured CRM data enrichment model can help teams decide which skipped records need basic contact validation, which need stronger account context, and which require deeper intent or behavioral signals before outreach.
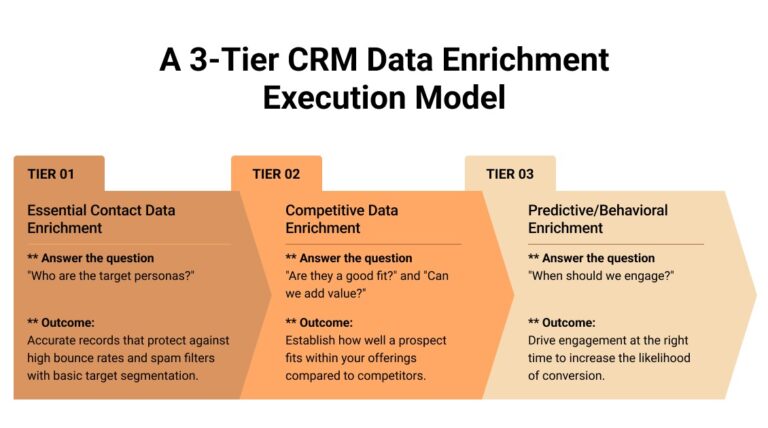
[Source: SunTec India | How to Enrich CRM Data for Better Audience Targeting and Lead Generation?CRM Data Enrichment ]
Recovering Skipped Leads through a Human Research Layer
Disabling AI SDRs is not the solution to improve outreach. The better response is to add a verification layer for the records it excludes. A human research layer reviews skipped contacts and re-qualifies records that the AI SDRs cannot validate on their own, by:
- Confirming the current decision-maker and correcting outdated titles
- Verifying emails and direct dials against multiple live sources
- Completing firmographic and contact gaps until a low-confidence record is ready for outreach
- Flagging genuinely inactive records
| A 2025 peer-reviewed study published in the International Journal of Advanced Research in Engineering and Technology (IJARET) shows that AI systems augmented with structured human validation achieve materially higher accuracy than AI-only workflows—particularly in high-risk decision environments.
Source: SunTec India |
The purpose of this review is not to override the AI sales agents on every excluded record. It is to separate genuinely unusable contacts from records that only need additional validation. Once corrected, these contacts can be returned to the CRM with updated titles, verified contact details, clearer account links, and a defined outreach status.
This turns the skipped pool into a structured review queue rather than an invisible loss. Over time, the same review process helps reduce avoidable skips because corrected records improve the data the AI prospecting agent evaluates in future campaigns. The work should be handled as a recurring data quality control process, not as a one-time data cleansing ritual after pipeline issues arise.
Conclusion
The next phase of sales automation will depend less on how many tasks machines can perform and more on how well teams govern the inputs behind those tasks. As revenue operations become increasingly data-led, clean, current, and reviewable records will define which organizations scale outreach responsibly and which ones mistake efficiency for progress. The companies that build this discipline now will be better positioned to protect future pipelines, improve decision-making, and make automation work as an extension of sales strategy rather than a substitute for it.

{kind=link}